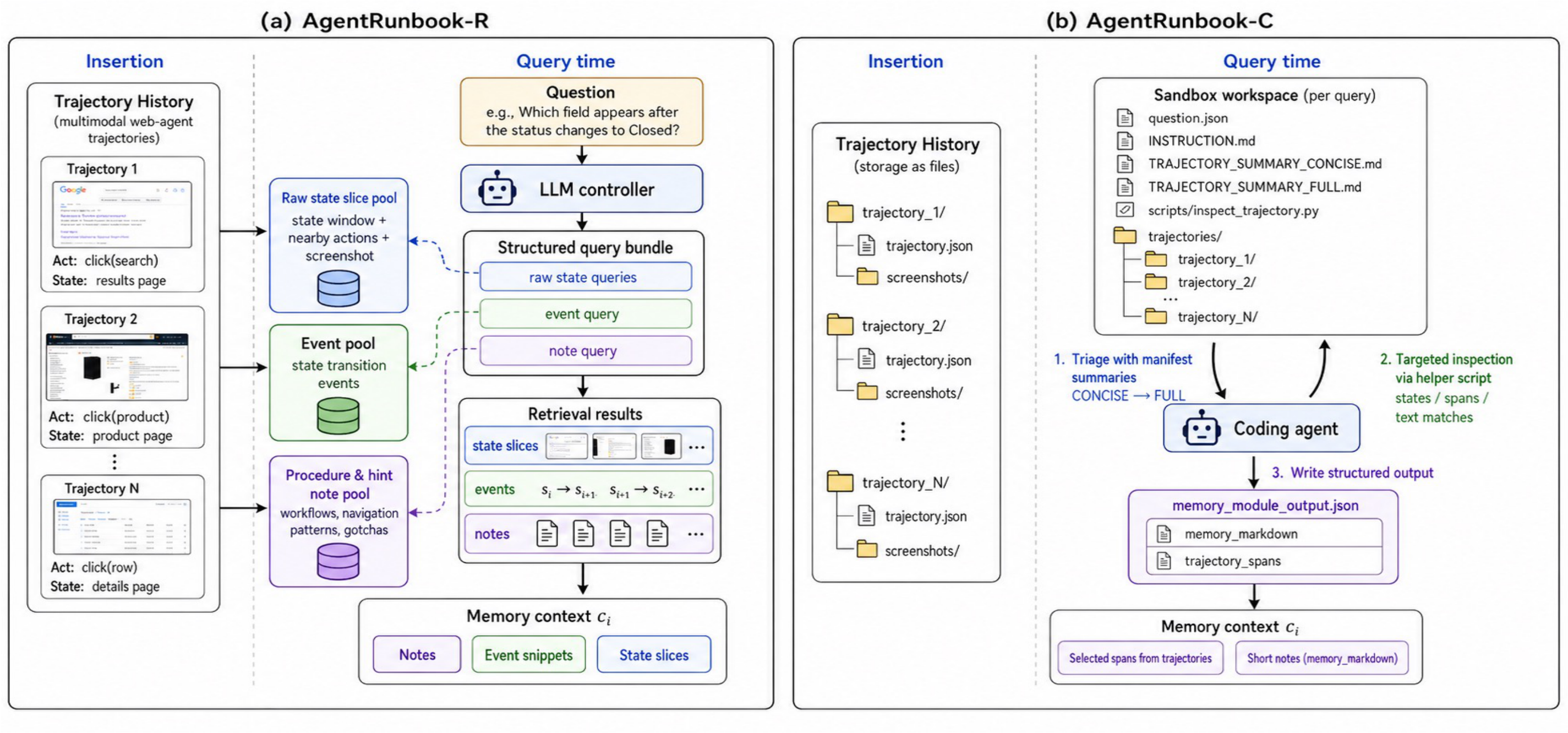
AgentRunbook-R
RAG memory with three knowledge pools for targeted recall.
- Raw state slices for fine-grained UI evidence.
- State transition events for environment dynamics.
- Procedure and hint notes for workflows and gotchas.
arXiv preprint
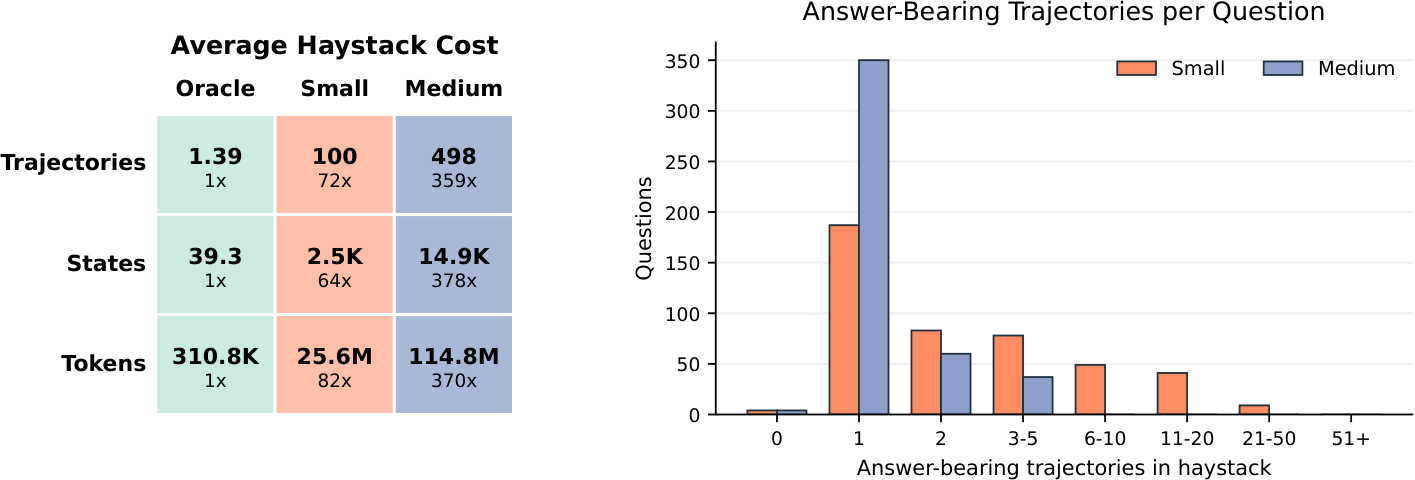
LongMemEval-V2 evaluates whether memory systems can help agents acquire the experience needed to become knowledgeable colleagues in customized environments. The benchmark pairs manually curated questions with long histories of multimodal web-agent trajectories. Memory systems consume the trajectory history and return compact evidence for downstream question answering. Both accuracy and query latency are targeted metrics.

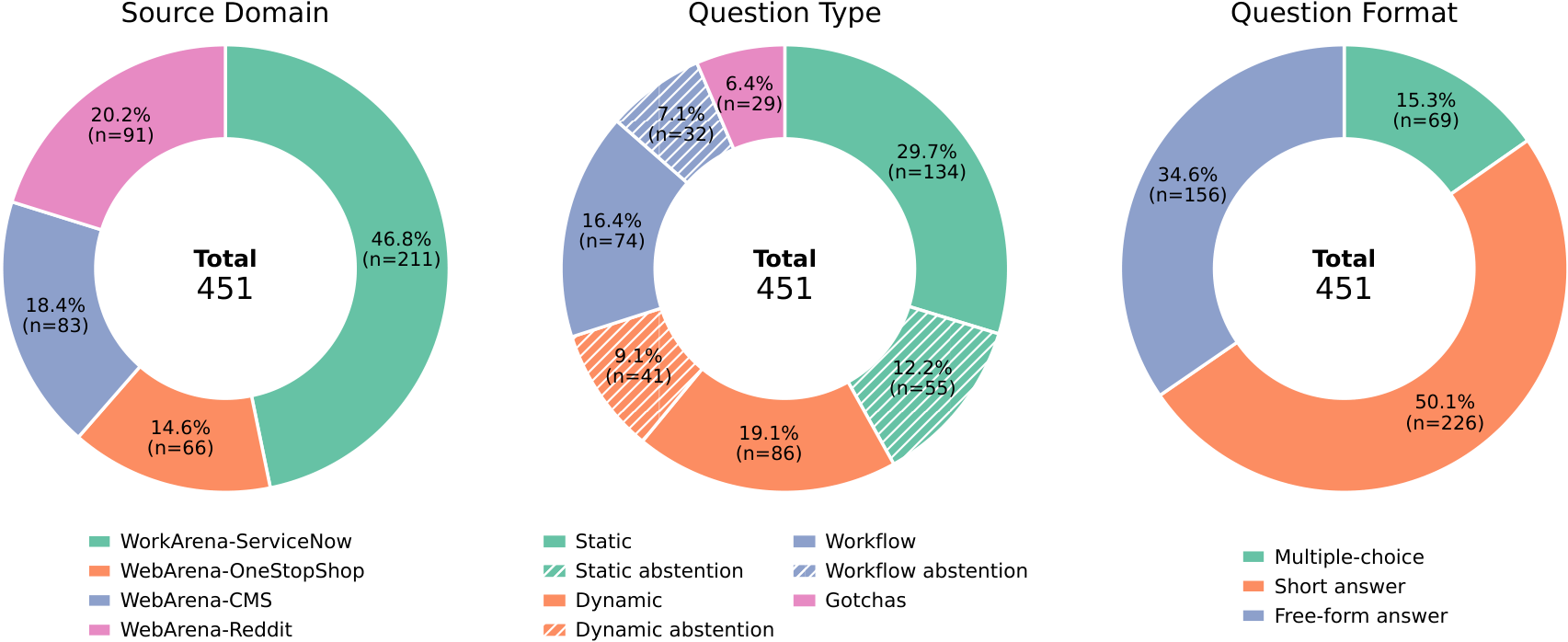
| Group | Benchmark | Domain | Sessions | Tokens | Context MM | Questions | Question MM | Static | Dynamic | Workflow | Gotchas | Premise |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| General long context | LongBench V2 | Mixed | N/A | 260K | No | 503 | No | Yes | No | No | No | No |
| General long context | MemoryAgentBench | Mixed | N/A | 285K | No | 2,071 | No | Yes | No | No | No | No |
| General long context | CL-Bench | Mixed | N/A | 10K | No | 1,899 | No | Yes | No | Yes | No | No |
| Conversational long context | LoCoMo | User-user chat | 28 | ~16K | Yes | 7,512 | No | Yes | Yes | No | No | Yes |
| Conversational long context | LongMemEval-V1 | User-assistant chat | 48-475 | 115K-1.5M | No | 500 | No | Yes | Yes | No | No | Yes |
| Conversational long context | PersonaMem | User-assistant chat | 5-60 | 26K-951K | No | 5,990 | No | Yes | Yes | No | No | No |
| Conversational long context | PersonaMem-v2 | User-assistant chat | 10-20 | 33K-124K | Yes | 5,000 | No | Yes | Yes | No | No | No |
| Conversational long context | BEAM | User-assistant chat | 4.5-100 | 124K-10M | No | 2,000 | No | Yes | Yes | No | No | Yes |
| Agentic long context | MemoryArena | Agent mixed | 7 | 40K+ | No | 766 | No | Yes | No | Yes | Yes | No |
| Agentic long context | AgentLongBench | Game agent | 1 | 31K-4M | No | 6,400 | No | Yes | Yes | No | No | No |
| Agentic long context | EMemBench | Game agent | 1 | 2K-infinity | Yes | 1,280+ | No | Yes | No | Yes | Yes | Yes |
| Agentic long context | FileGramBench | File-system agent | 12 | 11K | Yes | 4,333 | No | Yes | No | Yes | No | No |
| Agentic long context | AMA-Bench | Agent mixed | 1 | 57K | No | 2,496 | No | Yes | Yes | Yes | Yes | No |
| Agentic long context | LongMemEval-V2 | Web agent | 100-498 | 25M-115M | Yes | 451 | Yes | Yes | Yes | Yes | Yes | Yes |
A memory system implements the Insert and Query API.
We sequentially insert trajectories, then query for a length-bounded multimodal memory context per question. A fixed reader answers from that context.
Insert(h)
Query(q) → context
Reader(q, context) → answer
The evaluation reports answer accuracy and query latency.
RAG memory with three knowledge pools for targeted recall.
File-based memory that invokes a coding agent to gather evidence.
| Method | Family | Small Overall | Small Latency | Medium Overall | Medium Latency |
|---|---|---|---|---|---|
| No retrieval | Reader only | 1.3% | 0s | 1.3% | 0s |
| RAG: query to slice | RAG | 42.8% | 0.1s | 38.1% | 0.1s |
| RAG: query to slice + notes | RAG | 51.0% | 0.2s | 45.9% | 0.3s |
| AgentRunbook-R | RAG | 58.6% | 26.9s | 57.0% | 25.8s |
| Codex | Coding agent | 69.9% | 177.2s | 68.7% | 185.8s |
| AgentRunbook-C | Coding agent | 74.9% | 108.3s | 70.1% | 139.9s |
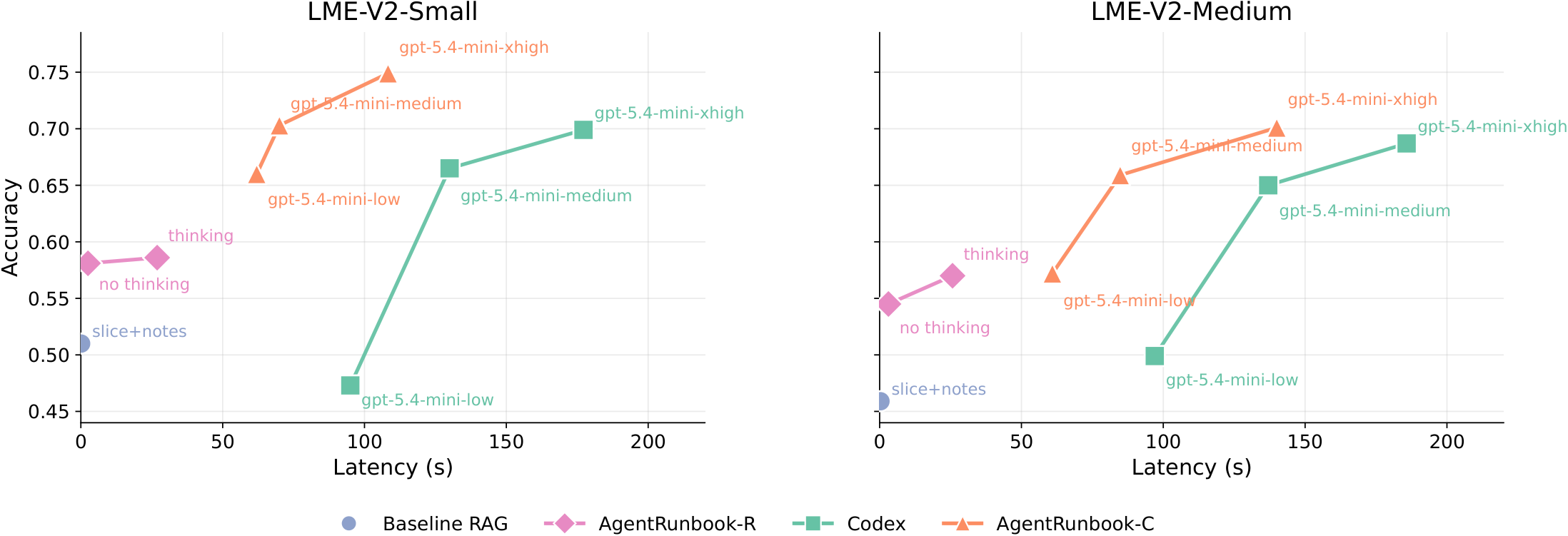
LongMemEval-V2 rewards memory systems that retrieve useful experience without making downstream agents wait. The leaderboard therefore uses a metric called LAFS Gain that captures how much a submitted system improves the accuracy-latency frontier formed by the released baselines and AgentRunbook.
For a set of operating points \(F\), let \(A_F(T)\) be the best accuracy available with query latency at most \(T\). We calculate LAFS as average reachable accuracy over log-scaled latency budgets:
We use \(T_{\min}=1\mathrm{s}\) and \(T_{\max}=200\mathrm{s}\). With fixed reference frontier \(F_{\mathrm{ref}}=\{\text{RAG slice+notes},\text{Codex},\text{AgentRunbook-R},\text{AgentRunbook-C}\}\), we score a submission \(S\) as:
A score of 0 means the method does not beat the released reference frontier at any latency budget.
| System | Method Family | |||||||
|---|---|---|---|---|---|---|---|---|
| Leaderboard entries coming soon. | ||||||||
| System | Method Family | |||||||
|---|---|---|---|---|---|---|---|---|
| Leaderboard entries coming soon. | ||||||||
@article{wu2026longmemevalv2,
title={LongMemEval-V2: Evaluating Long-Term Agent Memory Toward Experienced Colleagues},
author={Di Wu and Zixiang Ji and Asmi Kawatkar and Bryan Kwan and Jia-Chen Gu and Nanyun Peng and Kai-Wei Chang},
year={2026},
eprint={2605.12493},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2605.12493},
}